

Our goal was to build a web application to manage images and videos with custom tagging and the ability to query on the cloud with facial recognition.
The architecture is similar to the process followed in this blog, the post below covers Initech Global’s approach.

Timeline:
With only a short time window allotted, our mission was to create a customized facial recognition application to meet our clients specific requirements. The application was to be built from the ground up utilizing a mixed architecture approach, this would allow our team to meet the timeline while including all features requested.
Why build new?
Our decision to build new allowed us to meet the unique requirements provided by our client. Several image storage service providers can be found online (some even utilizing Lychee). None of these options fully encompassed the specific needs of our client outlined below:
- Custom tagging and searching
- Facial Recognition
- Expose APIs to serve pictures on internal or user facing applications
- Seamlessly load pictures from internal communication apps
- Video storage and facial recognition on videos
Image Repository:
The simplest route was to provision S3 buckets for this task and three buckets were created:
- 2 buckets: User Facing – for approved images and unapproved images
- 1 bucket: Used to store cropped faces to sending for a facial match
Rekognition
This is one of our favorite services of the 200+ services AWS offers. Below we’ve highlighted a few API’s which were fundamental in our success.
- Collection: Created a collection per environment, this was used to collect the face vectors in a file – not the actual picture
- Detect Faces: Gives us coordinates for every face in an image
BackEnd
Java-SpringBoot was coupled with a MySQL database as back-end utilizing Spring JPA for Dao. These tools helped create any CRUD rest services needed in a moments time. The rule of thumb was to never load a single image in memory of our back-end application, all images should be directly routed from the client to our image repository. If we chose to go entirely server-less, we would have opted for DynamoDB – MySQL fit our timeline more appropriately and gave us the ability to do aggregations, sorts, and pull stats with far less effort.
Security
Security should be viewed as one of the most important non-tangible assets of any organization, we viewed this as one of our major acceptance criteria for this web applications. It is even more important when content is moved to cloud and accessed from web. This doesn’t only apply to application security but how we securely share content between browser and AWS (without having our webserver in between causing bottleneck). This is how interaction happens
- Once user is successfully authenticated (Okta was used), we hit our back-end and based this on User Roles and buckets to which user can access in read/update mode, we create a custom IAM policy and generate a federation Token credentials with a preset expiry time and share it with front end
- On the client site, we refrain from storing it even in cookies or local storage, just use it from memory to interact with AWS resources
Browser to S3 Interaction
- Tokens provide all necessary access, all we now do is create presigned URL for downloading and uploading images
- Two different views for users to look at content
- Administrators – which directly calls an S3 List API to fetch the image list to manage all images
- Users – , which will fetch approved image locations from our image indexes in mySQL
- Uploading images happens straight to S3 and calls our REST API for indexing and facial recognition, the article will continue to explain in more detail
Image Sizes
- We decided to storage two variations of an image
- Actual image
- Thumbnail of the image with same aspect ratio and fixed height of 200px
- Both stored in same bucket with specific naming convention which can be easily differentiated
- We use thumbnails when the user is viewing images on the UI and we pull the actual image only when in full screen view or downloading
- If we were to make a recommendation – we would store a desktop size image as well, which can be used in slide show, because some of the high resolution images (> 15Mb) will take few seconds depending on bandwidth for downloading.
Serverless:
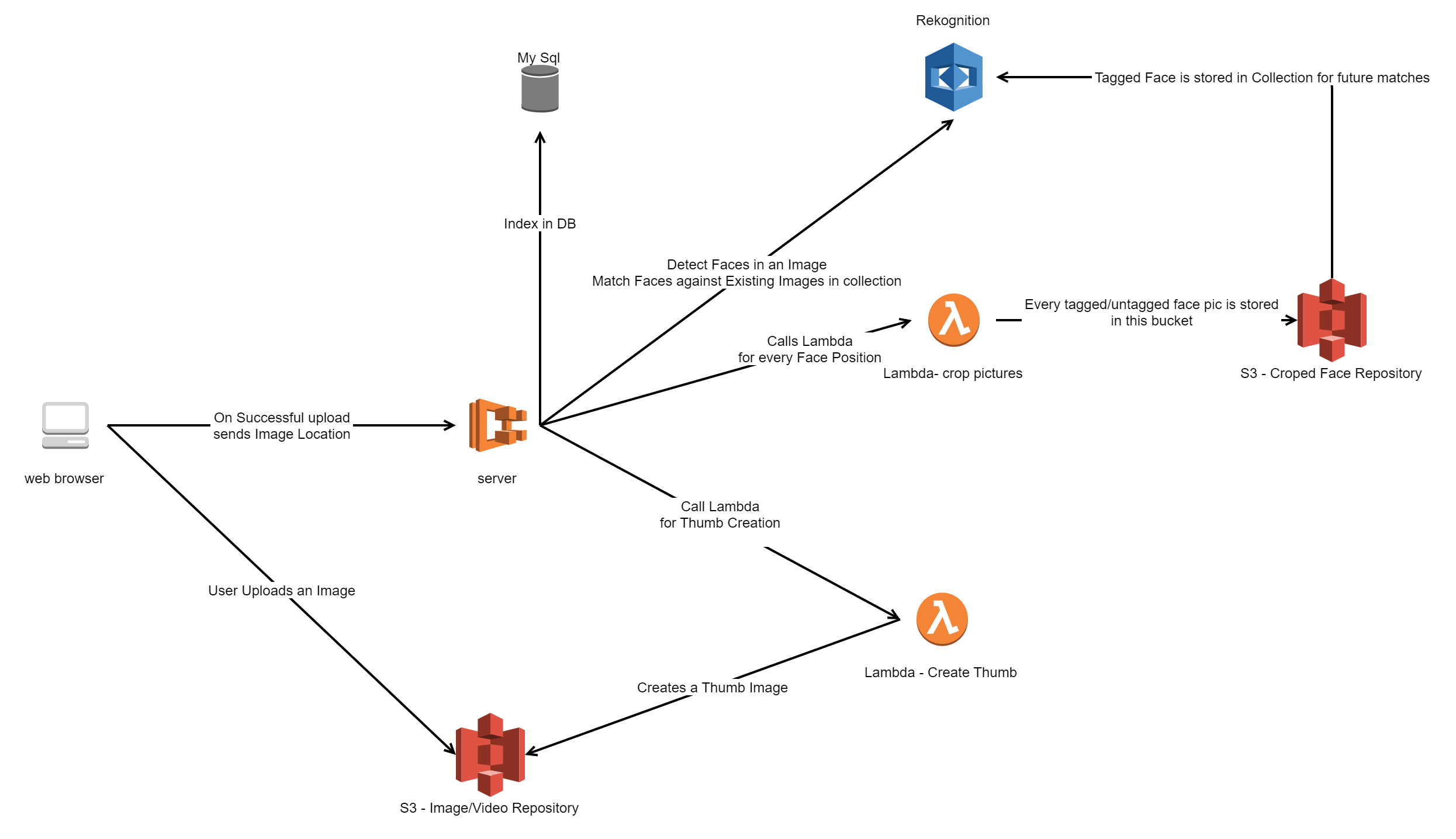
Images are not loaded in server which is setup as small machine(1 CPU / 512MB Memory). Two occasions exist where we’ll read the image in the back-end, both are offloaded to Lambdas. We didn’t trigger these Lambdas from S3, but called Lambdas from our back-end app asynchronously.
- One for creating the Thumbnail
- Second for cropping the faces out and store in a face bucket used for adding to collection
Uploading Process
- When user upload to S3 is success, we call Rest API to index it
- This process takes care of creation of Thumbnails, detecting and capturing faces in to face bucket, running facial recognition against existing collection, tag the faces found, index everything in mysql, etc,.
- This sounds like a lot on server, but Lambdas doing their job along side, everything happens in fraction of second
Here is a simplified view of upload process:
Tagging Faces
- User can tag undetected faces by clicking on face (shown on image above) and these tagged faces will then be indexed and created in the AWS Collection and used for future uploads
- There is a large appreciation for he AWS ‘Recognition’ service here, as it’s doing an incredible job detecting even low resolution faces, even with only 1 or 2 pictures matching from its collection.
Front-end
This was an easy choice. We’ve been huge fans of Angular since its very first release back in 2011. I will mention couple of interesting things we’ve learned:
- First step on a successful login or page refresh, before any component or service instantiations, we needed to get AWS federation credentials and initialize AWS SDK. We had to add ‘APP_INITIALIZER’ to providers and load a factory returning a promise which fetches and initializes AWS JS SDK.
- One of the pages where we implemented an infinite scroll for Thumbview against S3 loads,we used ngx-virtual-scroller , we faced some challenges when Thumb sizes are different and we don’t know how many images to preload in a single page without doing some crazy math summing up thumb widths and window widths, and intelligently filling the page with right number of images to fit the screen. Literally bugged us for couple of days. We later went with an easy route of clipping the image if aspect doesn’t fit the desired width (object-fit property).
Infrastructure
- Back end is dockerized and deployed to AWS ECS
- Static Front end is served from S3 with Cloudfront
- Cloudformation to create and deploy entire infrastructure
- Gitlab Pipelines triggering build and deploy on commits
