

Our goal is to highlight the ability to consume streaming data from AWS Kinesis, build a Datalake in S3 and run SQL queries from Athena.
The objective is to not only show our architecture but provide actual cloudformation to create an entire datalake in matter of minutes.
SourceCode:
If you understand the above architecture and want to jump right into actual code, here is a Link to Cloudformation template. Simply choose any stack name and create stack from the CloudFormation console or use AWS CLI. This will create all necessary resources including a test Lambda function to publish events to Kinesis. Run the test lambda from console using this sample JSON and observe the events in S3 buckets (in 60 seconds) and query from Athena.
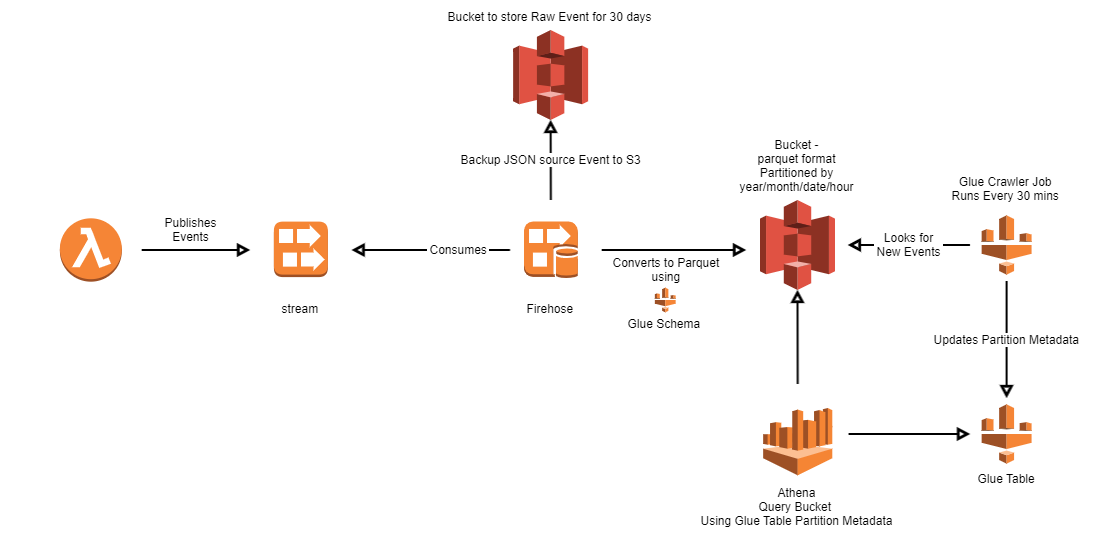
Overview:
- Running Test Lambda will publish events into Kinesis.
- Firehose consumes Kinesis events, backs up the source event into a raw event bucket(30 day retention), converts it to parquet format based on Glue schema and determines the partition based on current time and writes to final S3 bucket, our datalake.
- Glue Table holds all the partition information for S3 data.
- Glue Crawler Job runs every 30 minutes, looks for any new documents in S3 bucket and create/updates/deletes partition metadata.
- Run sql queries in Athena which uses Glue Table partition metadata to efficiently query S3.
Now lets go step by step and understand each resource in CF. Click on the heading will lead to actual resource in CloudFormation.
Data Storage:
Resources related to storing data in S3:
Bucket KMS Key
- KMS Key to encrypt data written to buckets
- Allow Firehose to use this key
Actual S3 Bucket
- S3 bucket, our actual data lake.
- Data stored in bucket is encrypted with KMS key
Raw S3 bucket
- S3 bucket to store raw JSON event
- Documents will be deleted after 30 days.
Streaming:
Kinesis Stream
- Kinesis stream with 1 shard (1 partition in Kafka language)
- Data in Kinesis encrypted with KMS.
Publish to Kinesis Lambda
- Test Lambda written in nodejs to publish events into Kinesis.
- Any code less than 4096 characters can be embedded right into CloudFormation
Lambda Execution Role:
All necessary policies for lambda function have been set here.
Kinesis Kms Key
- Key needed to encrypt data written kinesis data.
- key policy includes access to use for Lambda Role.
Stream Delivery:
DeliveryRole
- Role used by firehose needs several access polices.
- Some of them include access to Glue table, upload to S3 buckets, to be able to read streams, decrypt with KMS keys, etc.
Firehose
- Documents are partitioned when writing to S3. We can then give partition range in where conditions in Athena queries to avoid full bucket scan and save a lot of money and time.
![]()
- If any exceptions during conversions, firehouse will delivery these errors into separate partition(ErrorOutputPrefix)
- Buffering data every 60 seconds or 64Mb. Smaller than 64Mb is not recommended for parquet files(or that’s the minimum)
- Source events are backed up as is into a raw bucket in JSON and converted events are sent to actual bucket in parquet.
- Uses Glue Table Schema during conversion. If conversion errors, lets say timestamp is not in right format, events will be sent to exception S3 partition.
Glue Database:
Database to hold Glue Table.
Glue Table
- Format of the table ‘parquet’ is specified.
- Schema of the table is specified.
- Table creation is not mandatory. Crawler job will create the table automatically if table doesn’t exist, but crawler was inferring schema of some of the attributes like timestamp as strings. Because of this, Glue Table was created with our schema.
Crawler Role:
Role used by crawler job which needs access to read S3 bucket and use KMS key to decrypt s3 data.
Crawler Job
- Crawler job utilized behind the scenes and executes a simple spark code to crawl through our S3 bucket and updates the Glue Table partition metadata.
- Scheduled to run every hour at 15 & 45.
- Several configurations in aws documentation, I used what is suitable for our use case.
Once CloudFormation is executed, you should see all above resources created.
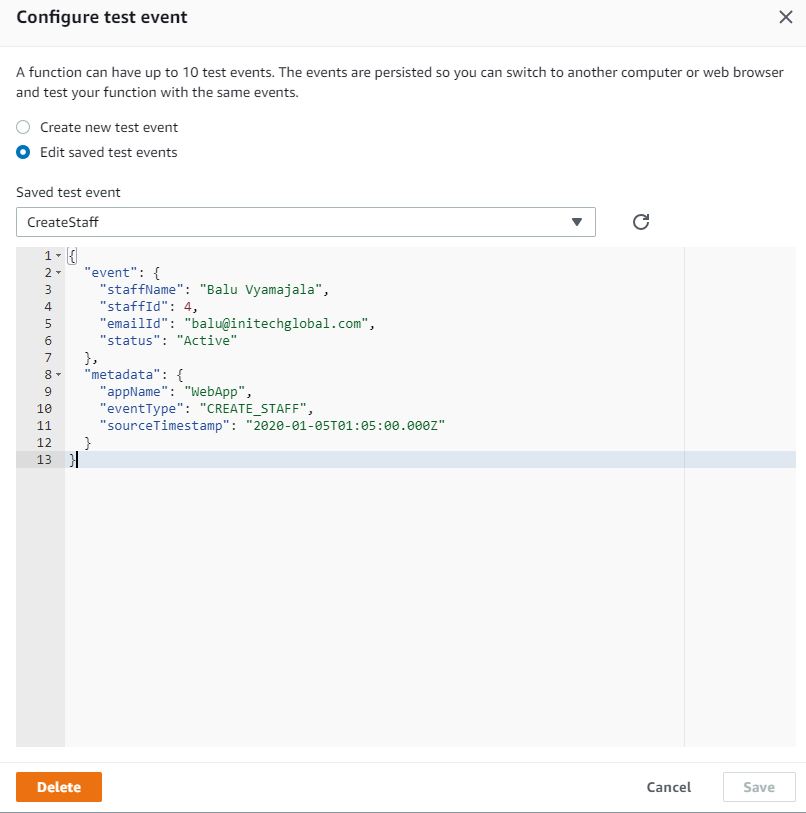
Run the Lambda from console with using this sample JSON event and you should see it S3 bucket in a minute.
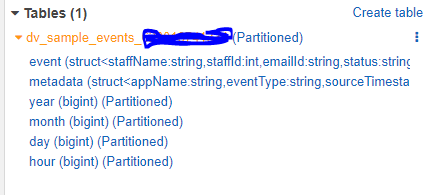
Wait for Crawler job to run or manually run it from console.

Athena or Glue, we can see the actual schema of the table we have given in template along with partitions.
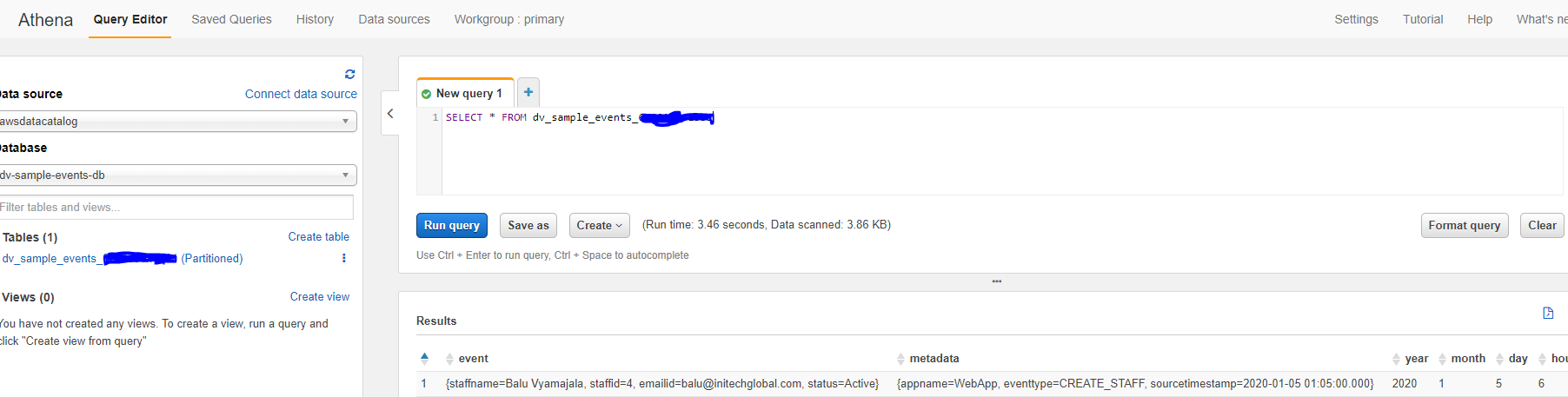
Select datasource and table and run queries from Athena!
I hope this is enough information to help you setup a simple datalake on S3 in no time.
