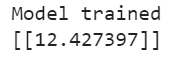
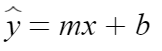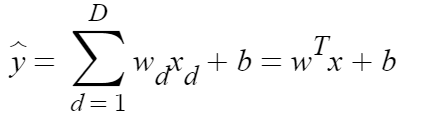Since our function has a one -to- one correlation-meaning for every x there is a –y- we can use a sequential model to map our data. Sequential models are only appropriate when our model has one input, is liner, and doesn’t require layer sharing.
Dense is the regular deeply-connected neural network layer. It is the most commonly used layer. It creates a matrix with biases created out of layers if the input to layer is greater than two. It then computes the dot product between the input and the kernel.
The unit is a positive Integer, representing the dimensionality of the output.
The model needs to know what input shape it should expect for a sequential model. The input shape returns as an integer shape, tuple, or list of shape tuples, one tuple per input tensor.
Next we will compile the model: